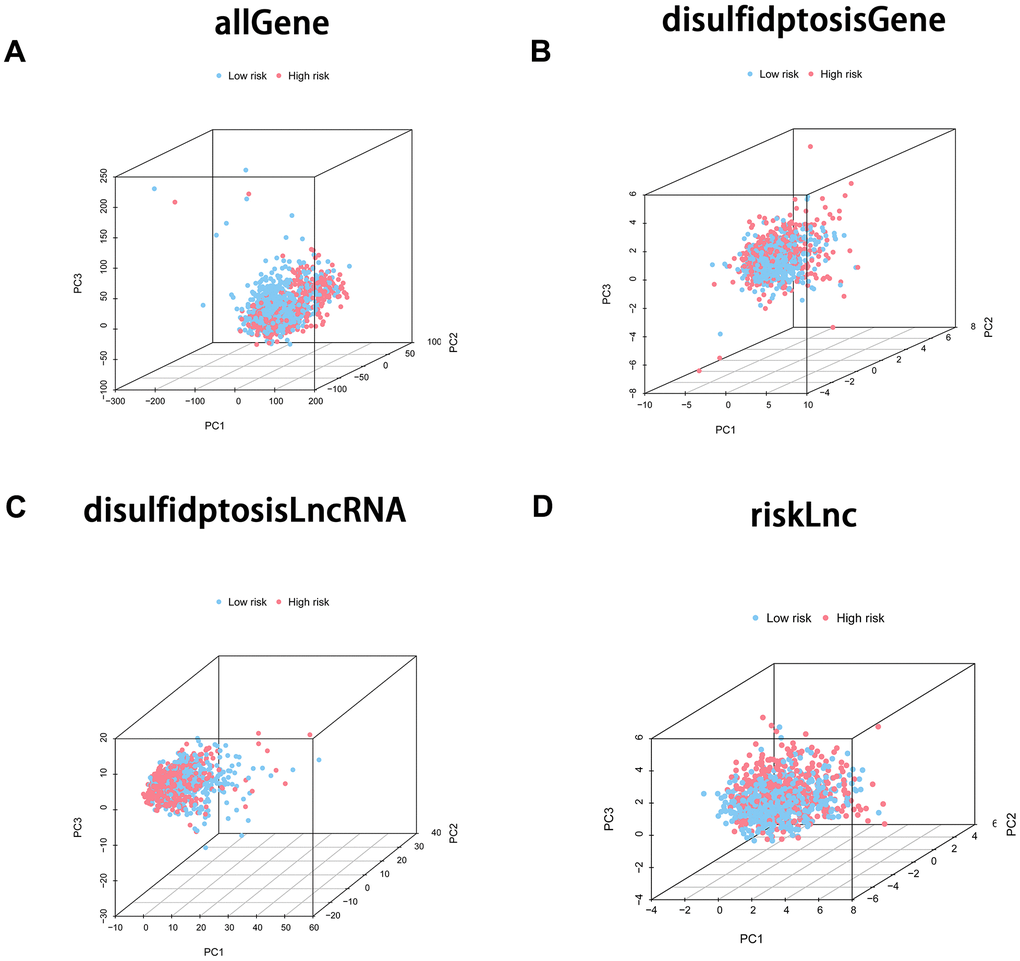
Figure 4.Principal component analysis (PCA) was employed to scrutinize the differentiation between the high-risk and low-risk groups employing diverse gene sets. The four PCA plots depict the sample distribution within the corresponding risk groups based on distinct gene sets: (A) incorporating all genes, (B) comprising disulfidptosis-associated genes, (C) encompassing disulfidptosis-associated lncRNAs, and (D) involving model lncRNAs. The PCA analysis sought to appraise the unique clustering patterns and the potential discriminatory efficacy of these gene sets in distinguishing high-risk from low-risk groups.