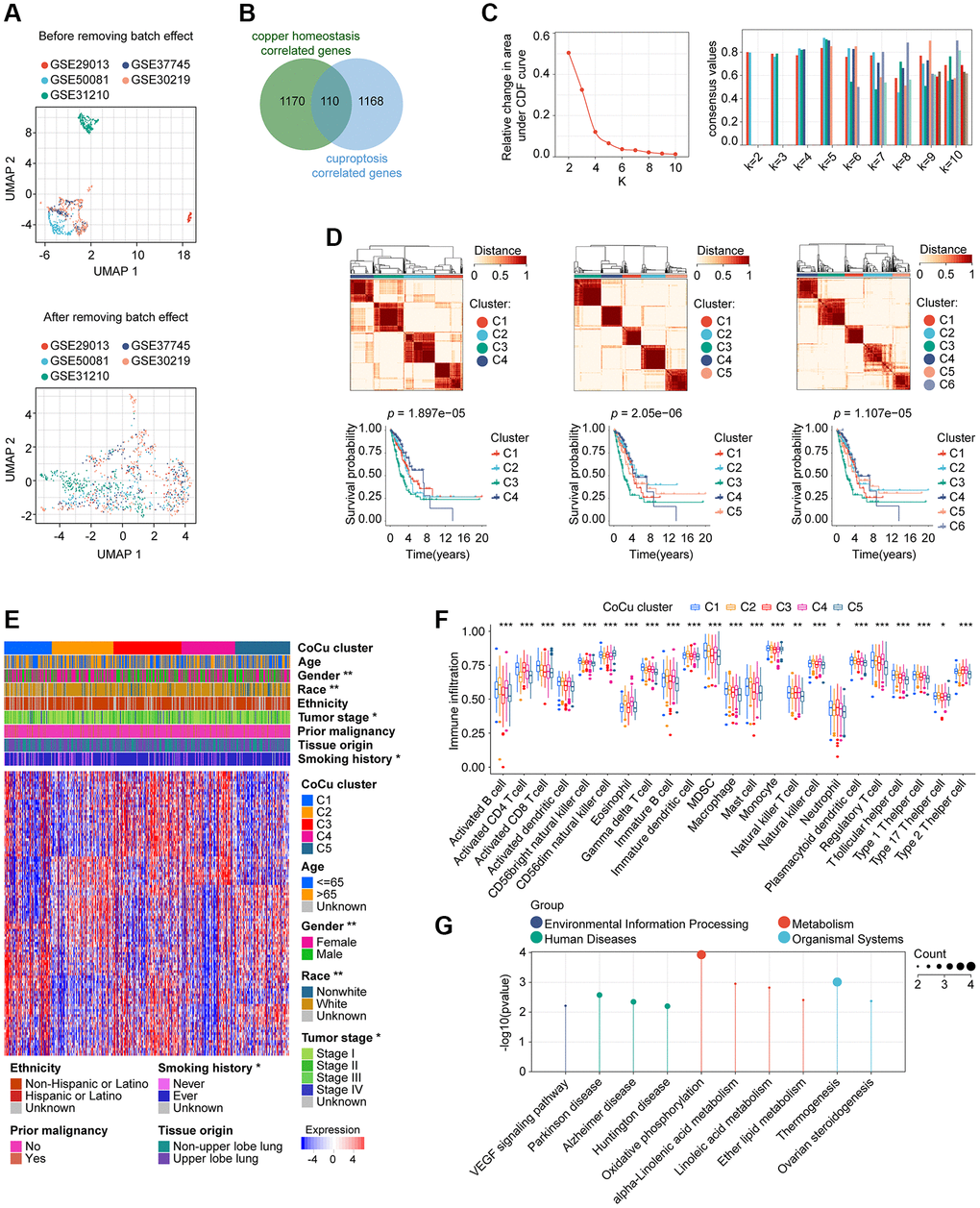
Figure 2.Removal of batch effects for the validation cohort and construction of the CoCu cluster. (A) The validation cohort is visually compared before and after the elimination of batch effects. The UMAP plot displayed at the top depicts the combined state of the GEO dataset before removing the batch effect. Conversely, the UMAP plot in the lower section illustrates that after removing the batch effect from the merged dataset, the samples are interwoven, providing proof of the effectiveness of batch effect removal. (B) 110 genes that correlate to both copper homeostasis and cuproptosis-regulated genes were identified using a Venn diagram. (C) CDF plot (left) showing the downward trend of the curve. Consensus plot (right) showing the consensus value at specific k value. (D) Based on the evidence provided from CDF and consensus plots, we were more interested in the clustering situation when k = 4, 5, and 6. Clustering diagrams (upper) for k = 4, 5, and 6. KM curves (lower) for each k value. (E) The heatmap depicts the correlation between CoCu clusters, clinical parameters, and 110 genes associated with copper homeostasis and cuproptosis. The asterisks indicate statistical differences between CoCu clusters. In the heatmap, each row corresponds to a specific gene, while each column corresponds to a particular sample. (F) The box plots illustrate notable variations in the distribution of all 23 immune cell types across the 5 CoCu clusters, indicating statistical significance. (G) KEGG that was performed using 72 CoCu-DEGs showing the top enriched pathways. CoCu clusters: clusters identified by copper homeostasis and cuproptosis correlated genes; CoCu-DEGs: differentially expressed genes identified among CoCu clusters; UMAP: Uniform Manifold Approximation and Projection; CDF: cumulative distribution function; KM: Kaplan–Meier estimator; DEGs: differentially expressed genes; KEGG: Kyoto Encyclopedia of Genes and Genomes; A statistically significant P-value was defined as being less than 0.05; The following notation was used: * for P-values less than 0.05, ** for P-values less than 0.01, and *** for P-values less than 0.001.