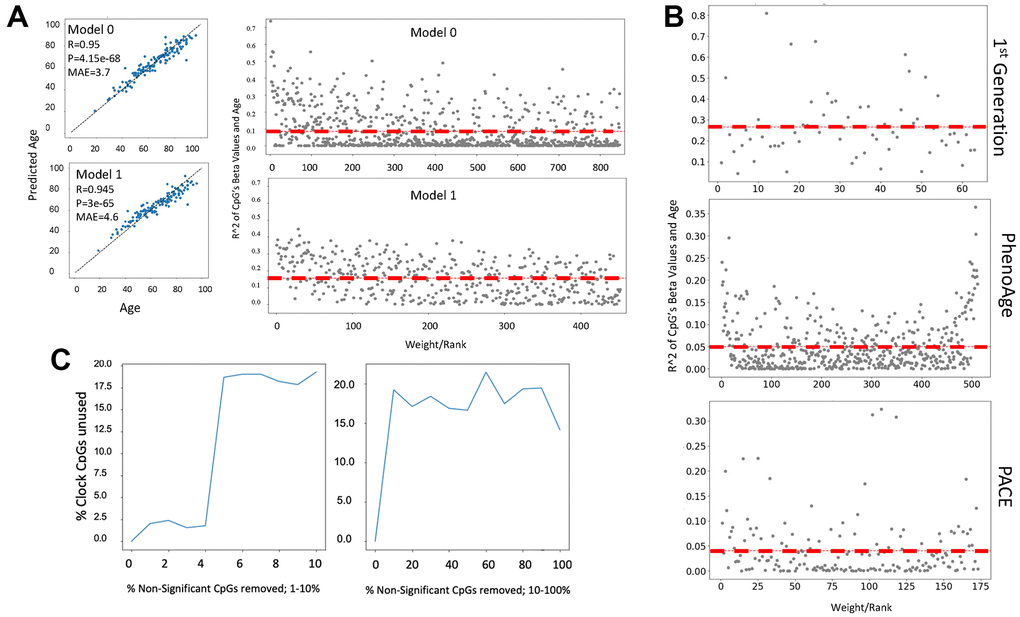
Figure 4.Cytosine ranking by EN is not based on the changes in methylation with age. (A) DNAme clock was constructed with EN regression on a 450K array dataset (GSE40279, N=656), and the test set prediction performance is shown (Model 0). The selected clock cytosines were removed, the model was retrained, and model performance on the test set is shown (Model 1). Scatter plot of the coefficient of variation for each clock cytosine individually regressed on age plotted against their rank by their absolute weights. The mean coefficient of variation of the clock cytosines are shown as red dashed lines. The cytosines of Model 1, e.g., those which were minimized to zero in Model 0, have a higher mean R2, despite being slightly less accurate. (B) Scatter plots of the coefficient of variation for the cytosines regressed on age are plotted against their rank/EN weights of the published 1st generation Hannum clock, PhenoAge and PACE. (C) An EN clock was trained with a 450K dataset (GSE40279), then non-clock cytosines were randomly removed: independently in a stepwise fashion. After each iteration of removal, a new EN model was trained and the selected set of cytosines was compared to the set of original clock cytosines. Non-clock cytosines were removed in one percent increments from 0-10% (left panel) and 10% increments from 10-100% (right panel). At 2% of removal of the non-clock cytosines, the cytosine set selected by EN began significantly changing. The percentage of unused original cytosines plateau at 17% in both gradual (1% at a time) and rapid (10% at a time) removal of the non-clock cytosines.