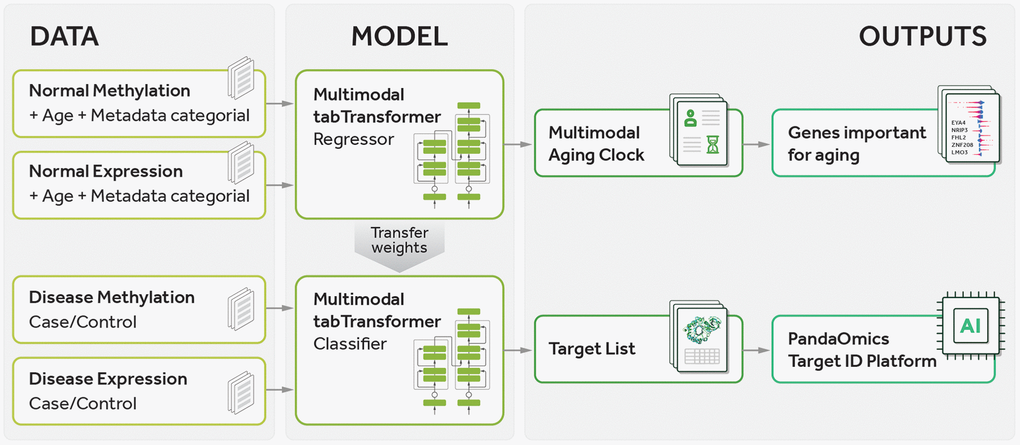
Figure 1.Pipeline of the current study. The pipeline involves training a multimodal transformer-based regressor on normal sample data to predict age, followed by transferring the learned weights to a transformer-based classifier for distinguishing between case and control samples. Gene prioritization is then performed using feature importance values obtained from the regressor to rank genes according to their relevance to aging and using importance values from the classifier to rank genes according to their relevance to both aging and disease. Finally, the gene lists are analyzed using the PandaOmics TargetID Platform.